
Efficient and Scalable ML System Design
Designing highly efficient and scalable ML systems that focuses on exploring multi-dimensional opportunities for fast training and inference on multi-scale complex architectures.
Designing highly efficient and scalable ML systems that focuses on exploring multi-dimensional opportunities for fast training and inference on multi-scale complex architectures.

System-oriented design methodologies for enabling future planet-scale VR/AR/XR systems, considering latency, perception, energy-efficiency, user experience, quality of service and edge-cloud top metrics.

Designing alternative quantum system execution model with compilation techniques, programming models and middle-ware layer over various future quantum hardware.
Co-Design for emerging HPC application cases on extreme heterogeneous architectures for both scale-up and scale-out efficiency.
Please join in us for cutting-edge system research talks from academia and industry labs ranging from novel ML chip design to scalable meta-verse design/optimisation.

SOAR Faculty Fellow, Director of FSA

Our lovely mascot! His specialty is sleeping hard.
Ph.D Student, Quantum Computing, Xanadu Intern

MPhil and upcoming Ph.D Student, ML system Design (Alibaba student fellow and Google Brain collaborator)

Ph.D Student, Accelerators, ML co-design, sparsity, large models scalability and acceleration (Alibaba Student Fellow, Google Brain collaborator)

Ph.D Student, Heterogeneous Memory Architecture Acceleration (ARC DP)

USYD Masters, upcoming Ph.D, Software-Hardware Co-Design, Bayesian Acceleration

Ph.D Student, Comprehensive Optimisation of Deep Learning: Efficient and Effective Algorithm and System Design (Co-supervised by Yibo@JD@KAUST)

Honours Student, Quantum Error Suppression

Honours Student, Quantum Compilation

MPhil student, ML System Design and Optimisation (co-advised with Sara Hooker and Amir Yazdanbakhsh @ Google Brain)

Honours Student, Dalyell scholar, Neural Architecture Search (NAS)

Masters Student, Meta-verse VR/AR Co-Design

Visiting student at FSA, Novel Graph Acceleration Engines.

Affiliated Researcher, postdoc at UTS, Quantum Algorithm.

Masters student, AR/VR Software Layer Design
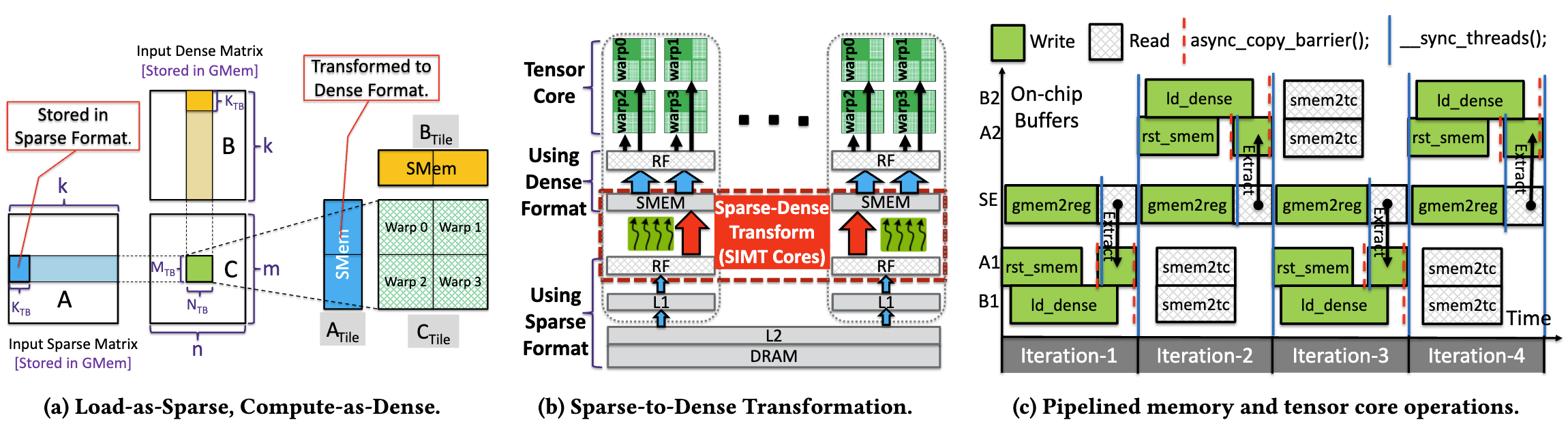
[VLDB'24]
Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference With Unstructured Sparsity'23
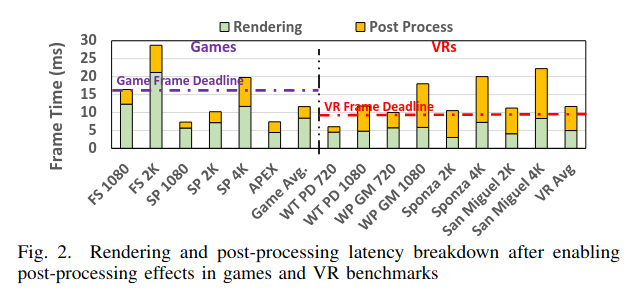
[HPCA'23]
"Post0-VR: Enabling Universal Realistic Rendering for Modern VR via Exploiting Architectural Similarity and Data Sharing, HPCA'23
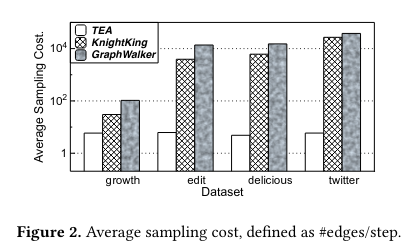
[EuroSys'23]
"TEA: A General-Purpose Temporal Graph Random Walk Engine, EuroSys'23
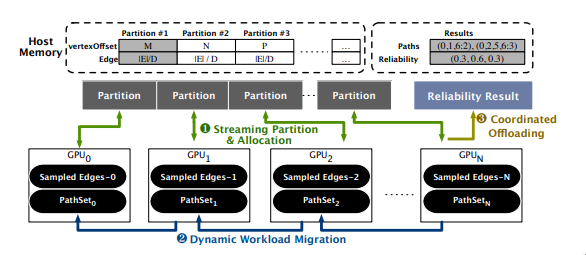
[ICS'22]
"Bring Orders into Uncertainty: Enabling Efficient Uncertain Graph Processing via Novel Path Sampling on Multi-Accelerator Systems", ICS'22
[PPoPP'22]
"Vapro: Light-weight Performance Variance Detection and Diagnosis for Production Run Parallel Applications", PPoPP'22
[ICDE'22]
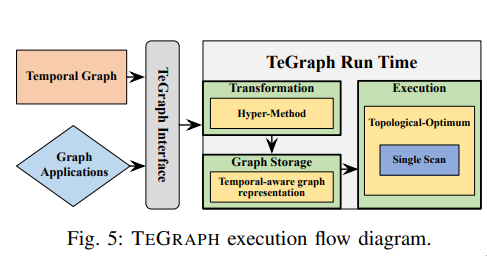
"TeGraph: A Novel General-Purpose Temporal Graph Computing Engine", ICDE'22
[MLSys'22]
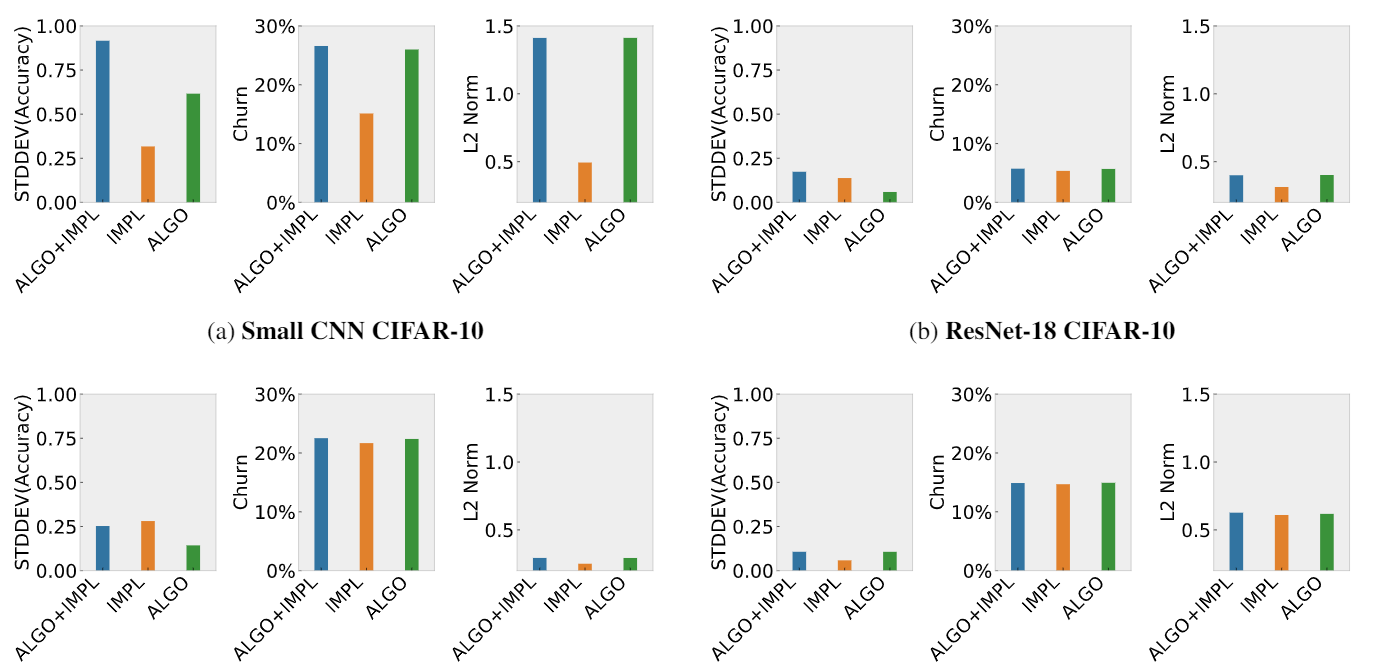
"Randomness In Neural Network Training: Characterising The Impact of Tooling"
Donglin Zhuang, Xingyao Zhang, Shuaiwen Leon Song, Sara Hooker (Google Brain), to appear in Machine Learning and Systems (MLSys) 2022. Artifact
[ASPLOS'22]
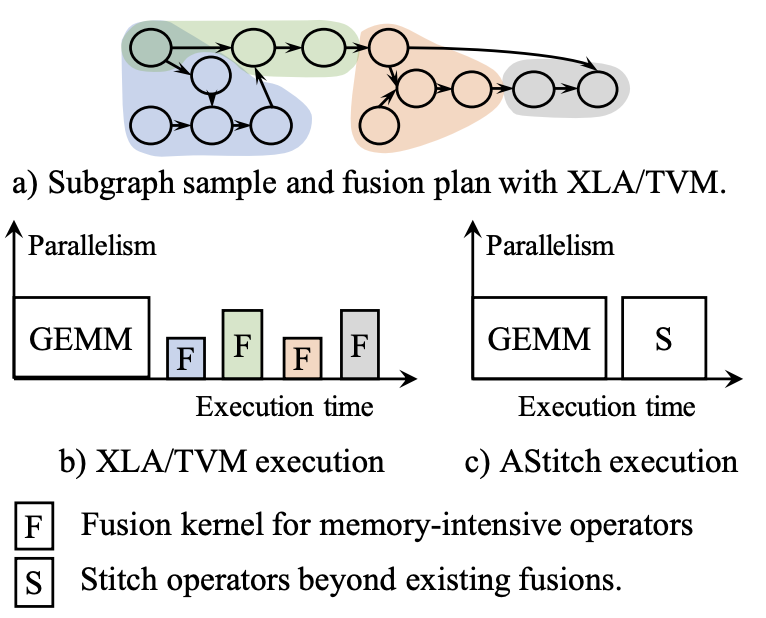
"AStitch: Enabling A New Multi-Dimensional Optimisation Space for Memory-Intensive ML Training and Inference on Modern SIMT Architectures"
In the proceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS'22) Artifact.
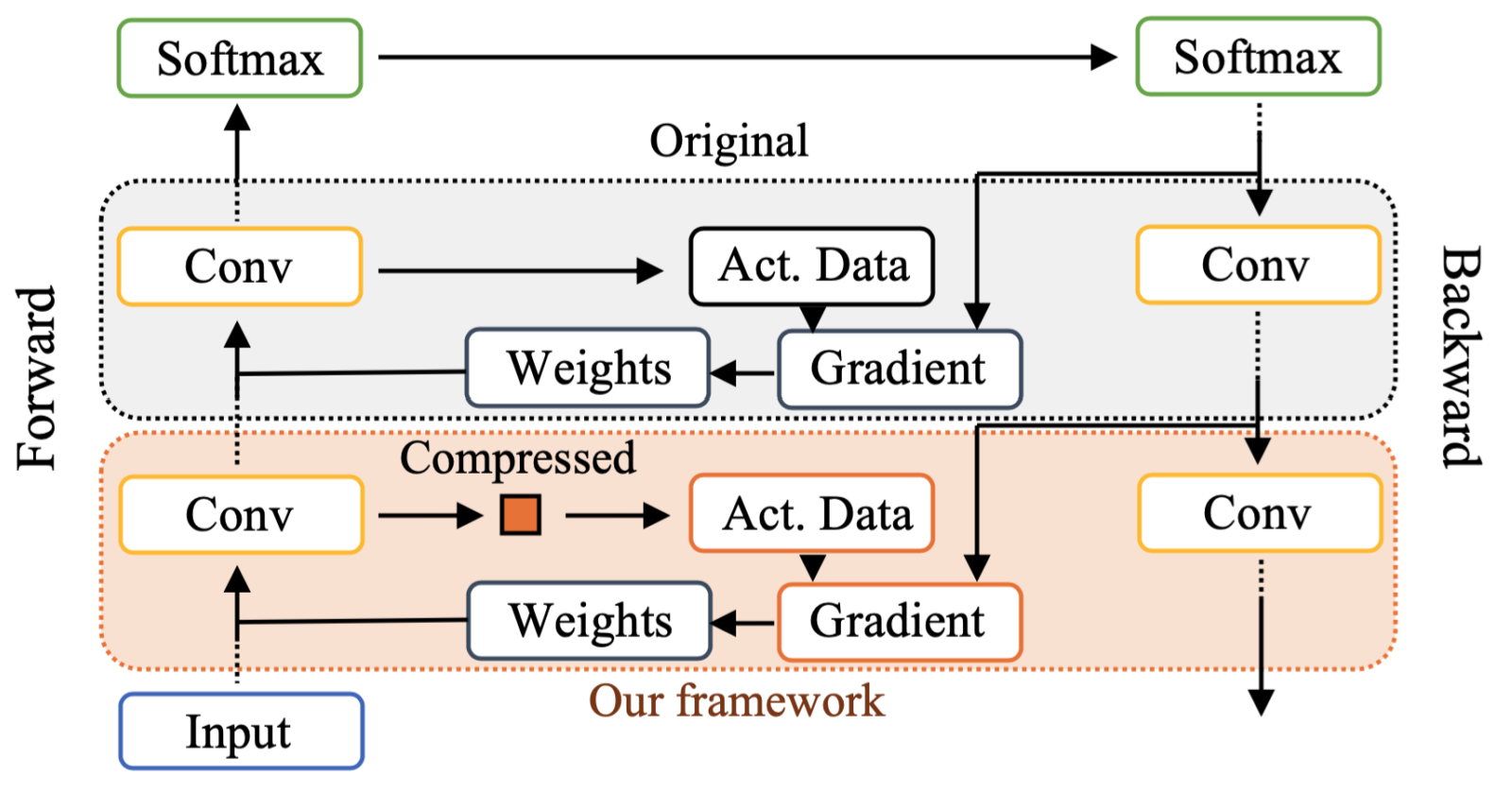
[VLDB'22]
"COMET: A Novel Memory-Efficient Deep Learning Training Framework by Using Error-Bounded Lossy Compression"
To appear in the 48th International Conference on Very Large Data Bases (VLDB'22)
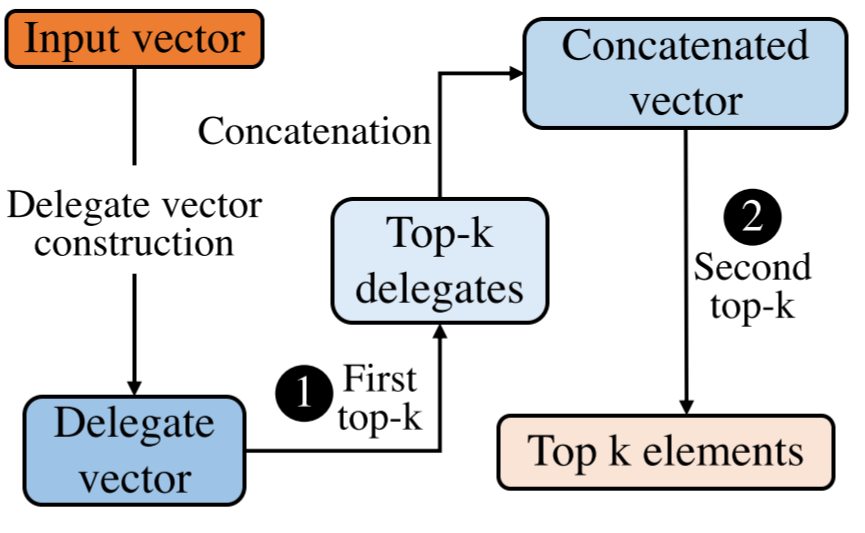
[SC'21]
"Dr. Top-k: Delegate-Centric Top-k on Heterogeneous HPC Architectures"
To appear on The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC'21). Artifact
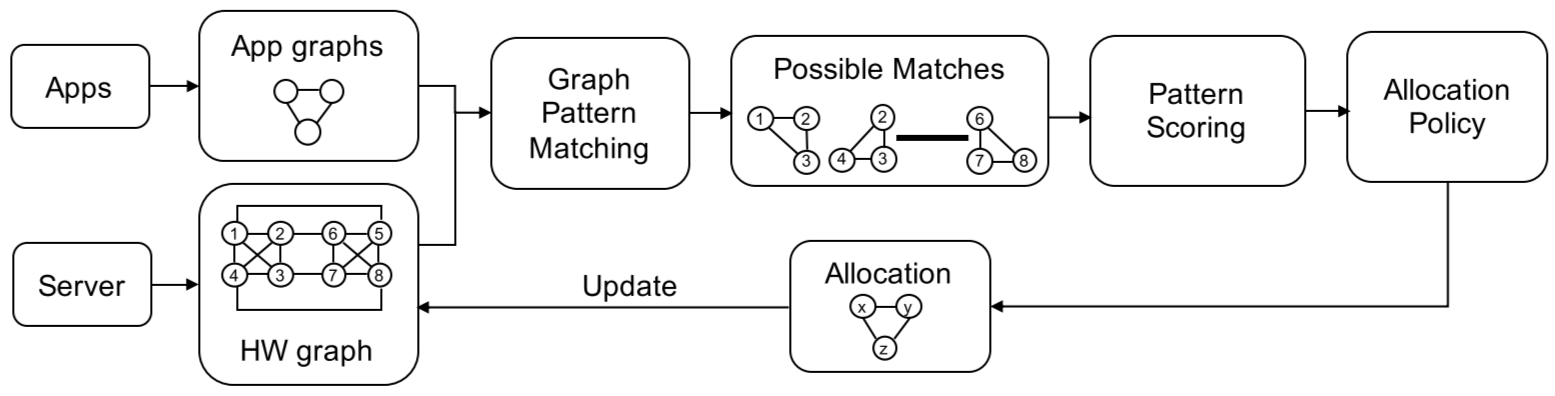
[SC'21]
"MAPA: Multi-Accelerator Pattern Allocation Policy for Multi-Tenant GPU Servers"
To appear on The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC'21). Artifact
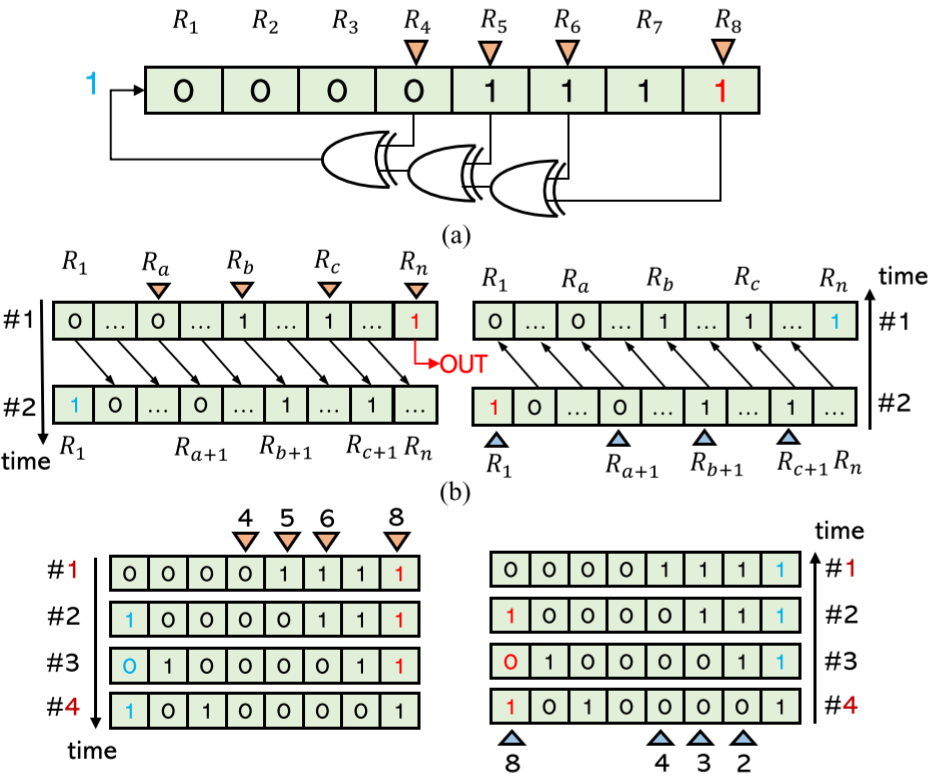
[MICRO'21]
"Shift-BNN: Highly-Efficient Probabilistic Bayesian Neural Network Training via Memory-Friendly Pattern Retrieving"
Qiyu Wan, Haojun Xia, Xingyao Zhang, Lening Wang, Shuaiwen Leon Song and Xin Fu, IEEE/ACM International Symposium on Microarchitecture 2021 (MICRO'21). Artifact
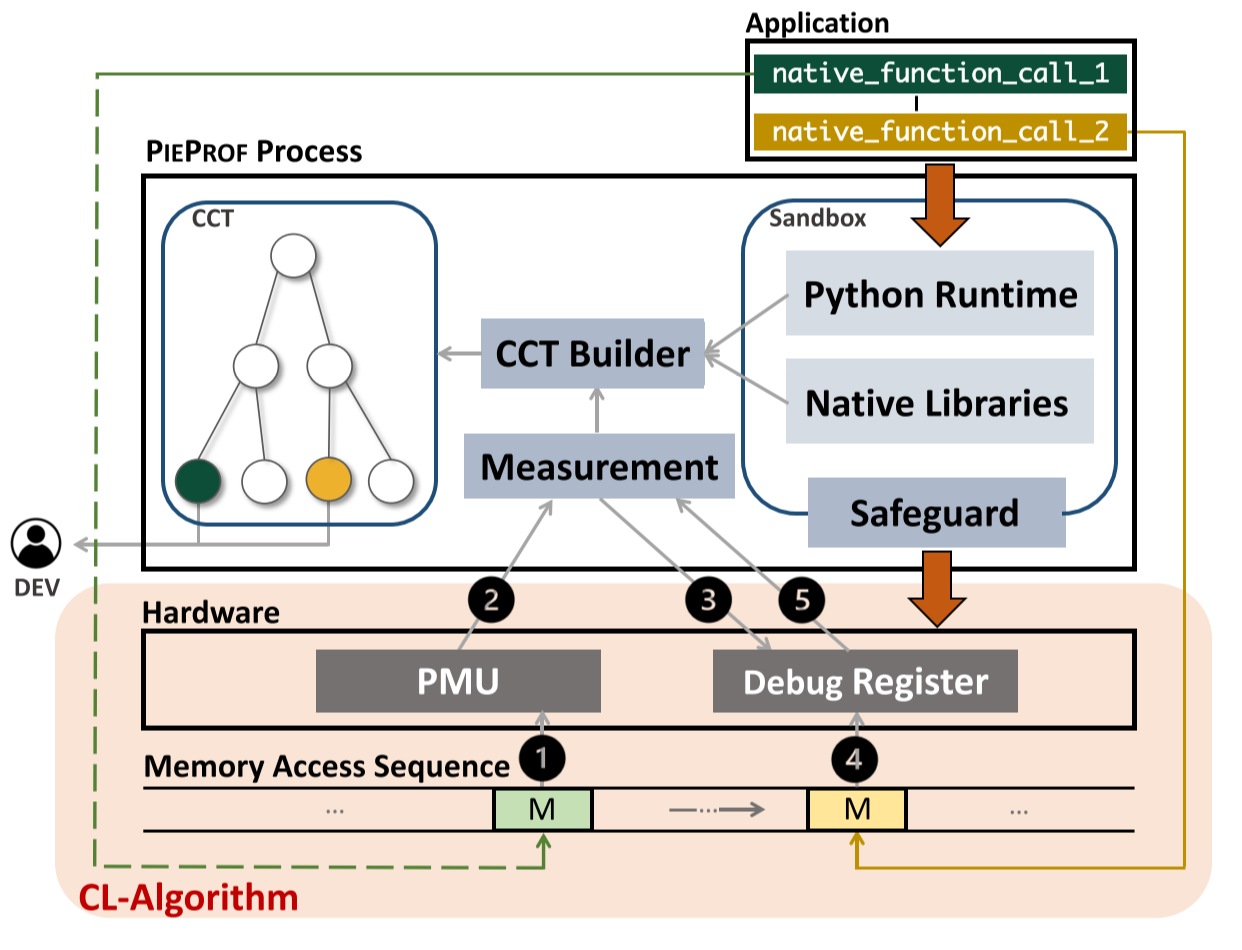
[ESEC/FSE'21]
"Toward Efficient Interactions between Python and Native Libraries"
Jialiang Tan, Yu Chen, Zhenming Liu, Bin Ren, Shuaiwen Leon Song, Xipeng Shen, Xu Liu, The ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE) 2021.
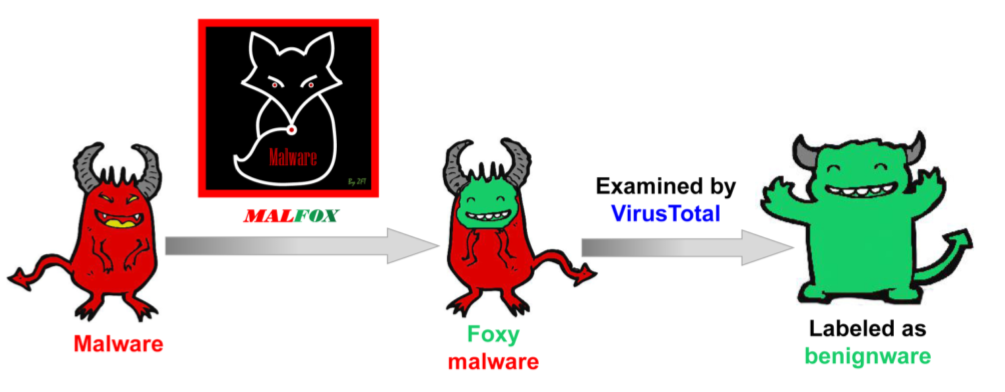
[TC'21]
"MalFox: Camouflaged Adversarial Malware Example Generation Based on Conv-GANs Against Black-Box Detectors"
Fangtian Zhong, Xiuzhen Cheng, Dongxiao Yu, Bei Gong, Shuaiwen Song, Jiguo Yu, IEEE Transactions on Computers.
[ICS'21]
"ClickTrain: Efficient and Accurate End-to-End Deep Learning Training via Fine-Grained Architecture-Preserving Pruning"
Chengming Zhang, Geng Yuan, Wei Niu, Jiannan Tian, Sian Jin, Donglin Zhuang, Zhe Jiang, Yanzhi Wang, Bin Ren, Shuaiwen Leon Song, Dingwen Tao, The International Conference on Supercomputing.
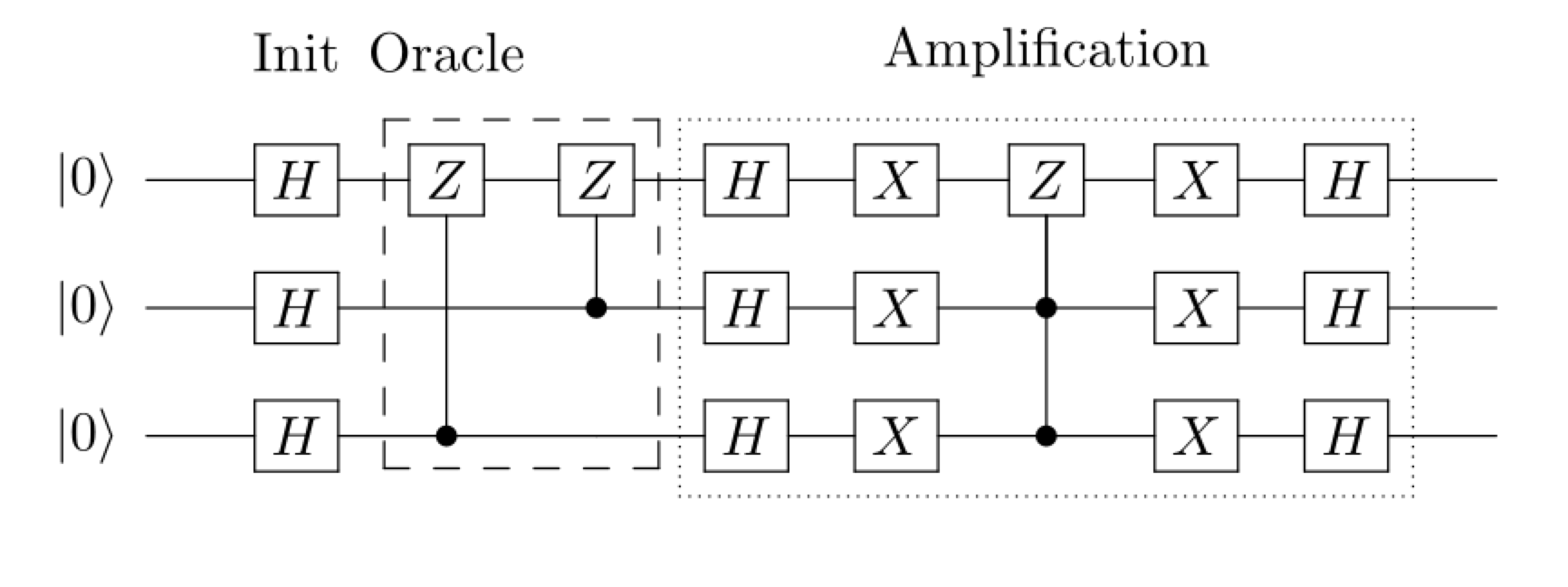
[ASPLOS YArch'21]
"Quantum Von Neumann Architectural Modelling for Algorithm Analysis"
Alan Robertson, Shuaiwen Leon Song, The third Young Architect Workshop (YArch), in conjunction with ASPLOS'21, April 2021. Talk
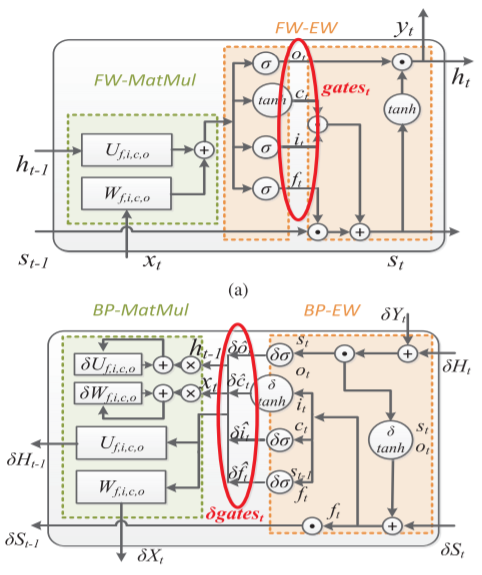
[ISCA'21]
"η-LSTM: Co-Designing Highly-Efficient Large LSTM Training via Exploiting Memory-Saving and Architectural Design Opportunities"
Xingyao Zhang, Haojun Xia, Donglin Zhuang, Hao Sun, Xin Fu, Michael Taylor, Shuaiwen Leon Song, The International Symposium on Computer Architecture [ISCA'21]. (Acceptance rate: 18.7%). Presentation
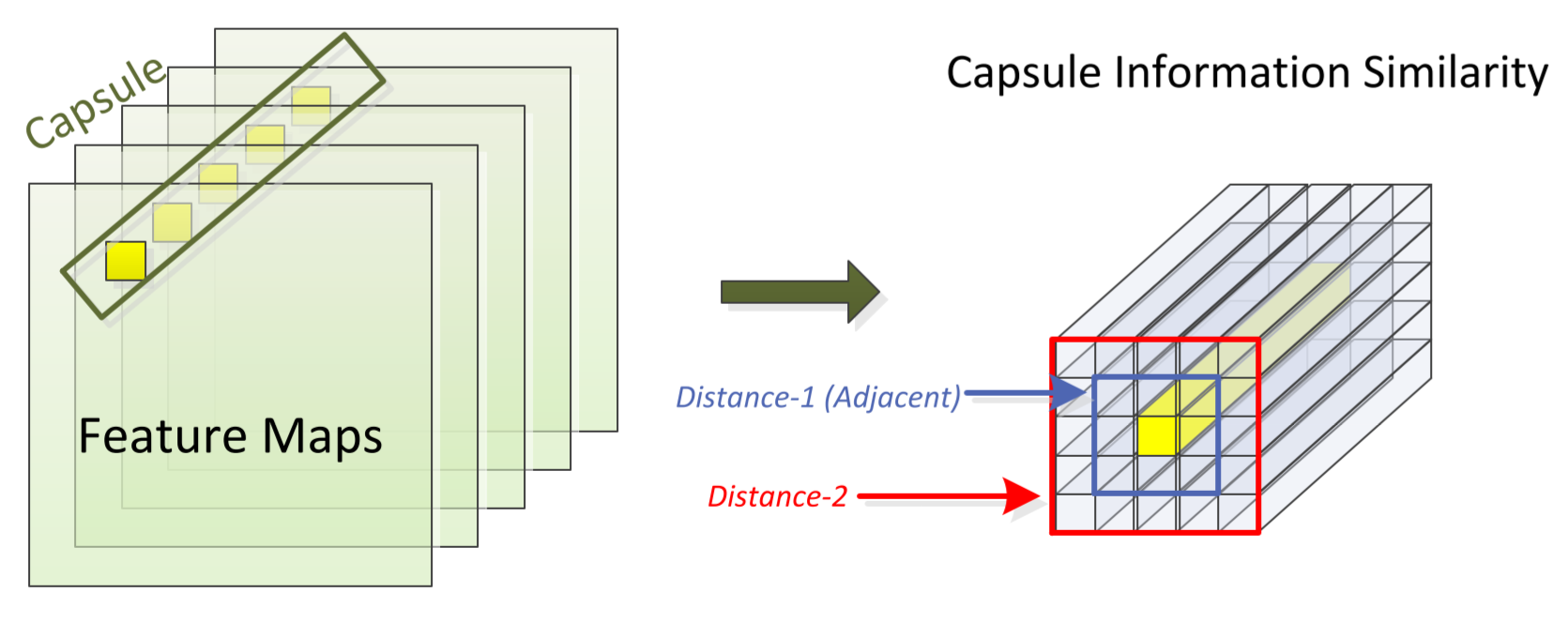
[TC]
"Enabling Highly Efficient Capsule Networks Processing Through Software-Hardware Co-Design"
Xingyao Zhang, Xin Fu, Donglin Zhuang, Chenhao Xie, Shuaiwen Leon Song, IEEE Transactions on Computers, A special issue on research highlights of Computer Architecture for 2019-2020 .
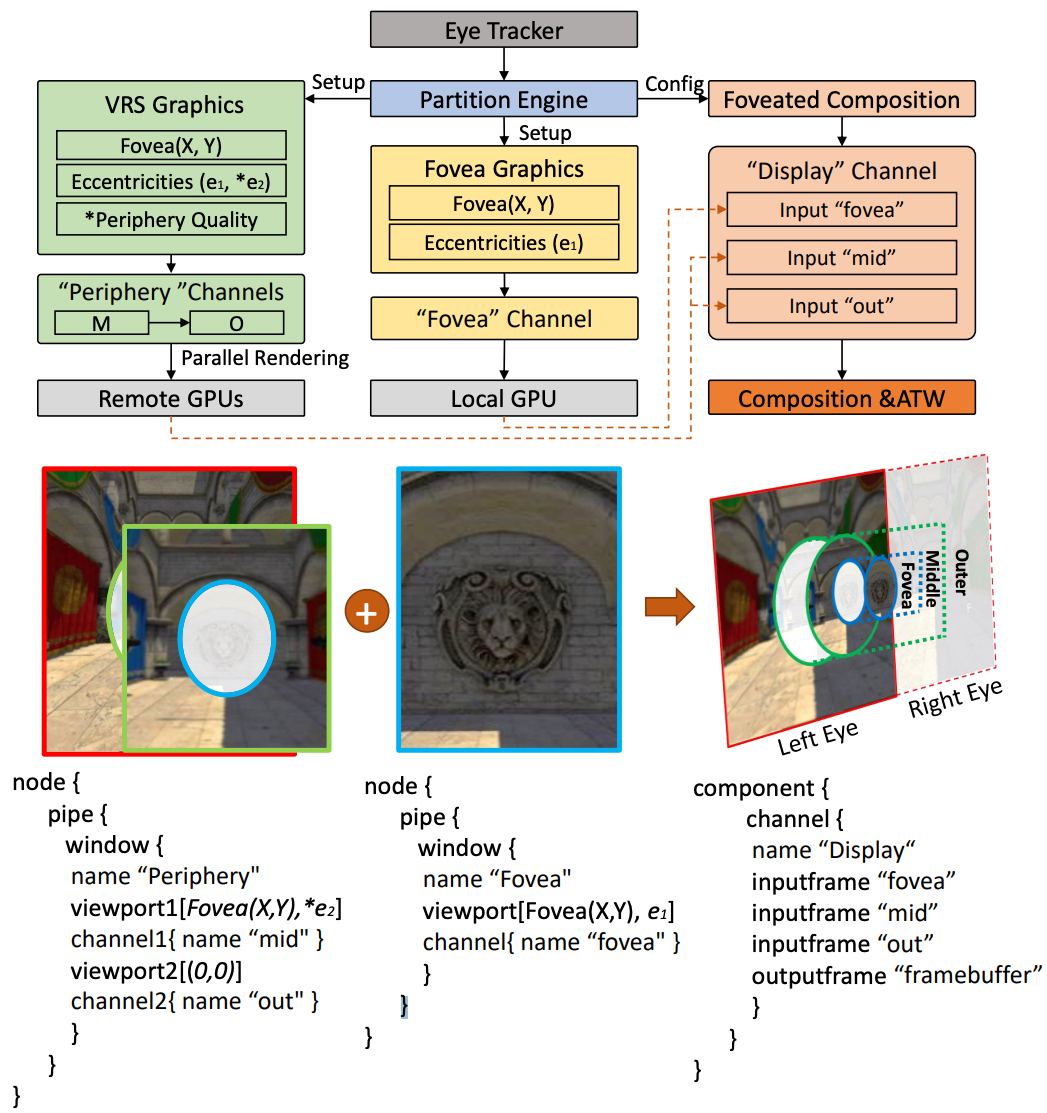
[ASPLOS'21]
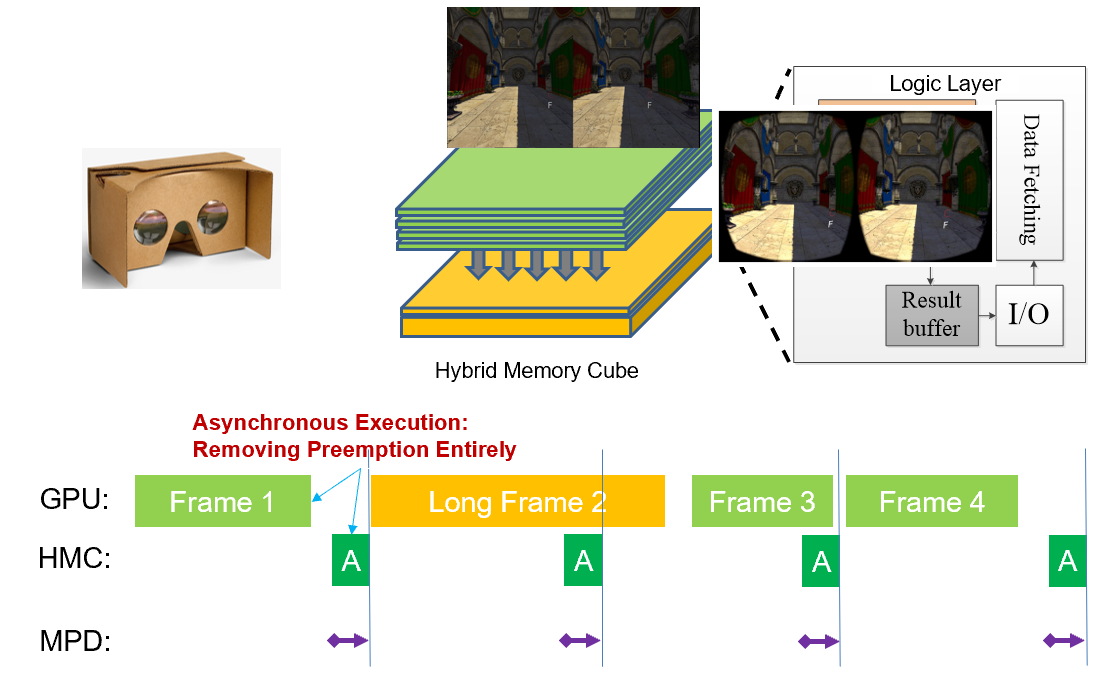
"Q-VR: System-Level Design for Future Collaborative Virtual Reality"
Chenhao Xie, Xie Li, Yang Hu, Huwan Peng, Michael B. Taylor, Shuaiwen Leon Song, The 26th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS'21). (Acceptance rate: 17.5%). This is the first work in the computer architecture community on a possible design for future planet-scale mobile VR systems with low latency and high quality. We transform a complex multi-dimensional problem into a system design problem, providing real-world observations, practical insights and a software-hardware co-design solution.
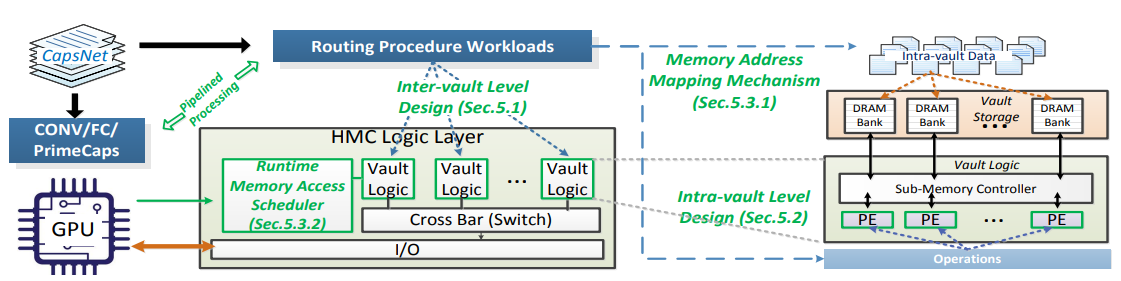
[HPCA'20]
"Enabling Highly Efficient Capsule Networks Processing Through A PIM-Based Architecture Design"
2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), (Acceptance rate: 19.4%; This work tries to start some conversation on how we deal with these new types of hybrid network structures where not only 2D or 3D convolution poses as the most significant efficiency block. We are helping CapsuleNet actually scale and become hardware-friendly (via Processing-in-Memory).)
Slides
[ISCA'19]
"OO-VR: NUMA friendly object-oriented VR rendering framework for future NUMA-based multi-GPU systems"
Chenhao Xie, Xin Fu, Mingsong Chen, Shuaiwen Leon Song. In Proceedings of the 46th International Symposium on Computer Architecture (ISCA '19). (Acceptance rate: 16.9%) Investigating into what future chiplet-based cloud server systems will look like to reach scalable parallel rendering efficiency via a new hardware-software co-design framework.)
Presentation
[HPCA'19]
"PIM-VR: Erasing Motion Anomalies In Highly-Interactive Virtual Reality World with Customised Memory Cube"
Chenhao Xie, Xingyao Zhang, Ang Li, Xin Fu, Shuaiwen Leon Song. In 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA). (Acceptance rate: 19.7%; One of the first papers in the community identifying that state-of-the-art software-level reprojection optimisation for commercial VR devices involuntarily causes significant hardware-level bottlenecks and motion anomalies.)
Video
[SC'19]
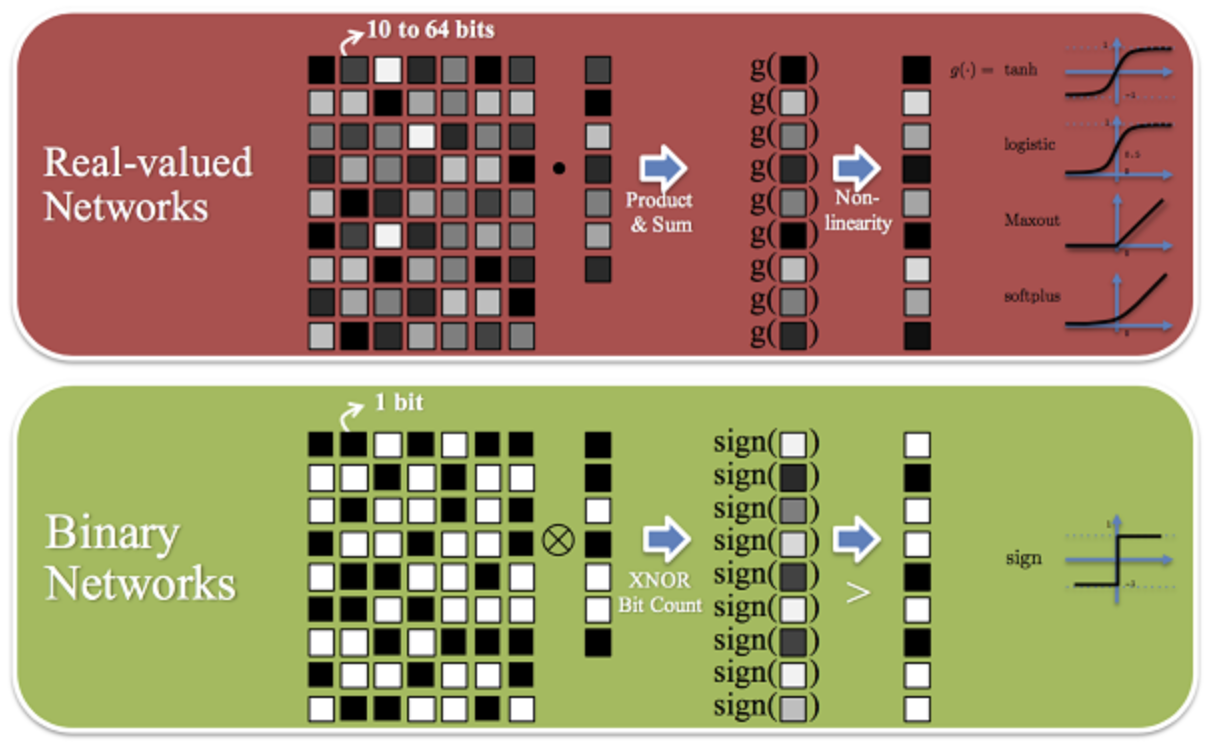
"BSTC: a novel binarized-soft-tensor-core design for accelerating bit-based approximated neural nets"
Ang Li, Tong Geng, Tianqi Wang, Martin C. Herbordt, Shuaiwen Leon Song, Kevin J. Barker. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC '19). (Acceptance rate: 20.9%; Introducing the concept of software-based tensor core for bit-level parallelism on many core accelerators)
Video
[PPoPP'18]
"Superneurons: dynamic GPU memory management for training deep neural networks"
Linnan Wang, Jinmian Ye, Yiyang Zhao, Wei Wu, Ang Li, Shuaiwen Leon Song, Tim Kraska. In Proceedings of the 23rd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP '18). (Acceptance rate: 20%; GPUs' memory are too small to have balanced efficiency matching with powerful cores when handling training for large non-linear networks. SuperNeurons helps users tackle this
Video

[HPCA'18]
"Perception-Oriented 3D Rendering Approximation for Modern Graphics Processors."
Chenhao Xie, Xin Fu, Shuaiwen Leon Song. In 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA). (Acceptance rate: 19.7%; Connecting architectural bit stream and its manipulation to user perception impact.)
Video
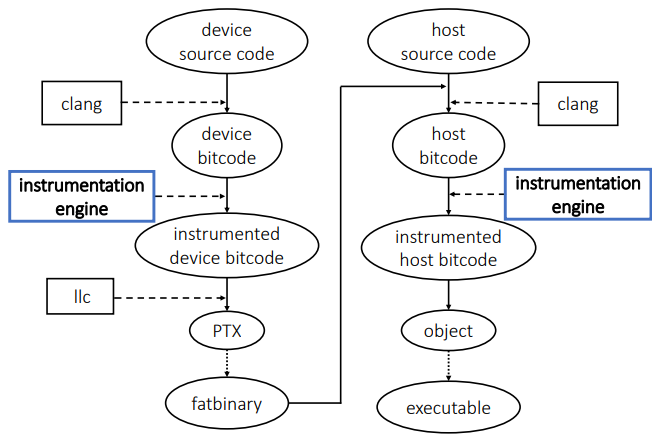
[CGO'18]
"CUDAAdvisor: LLVM-based Runtime Profiling for Modern GPUs."
Du Shen, Shuaiwen Leon Song, Ang Li, Xu Liu. In ACM International Symposium on Code Generation and Optimisation (CGO).
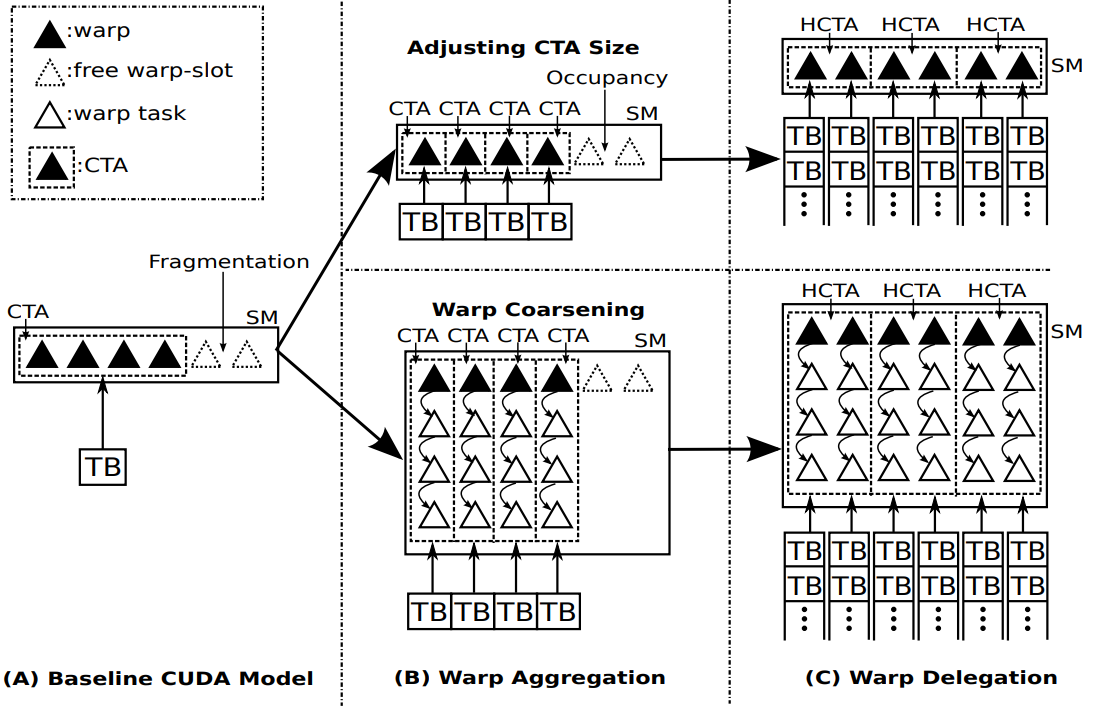
[ICS'18]
"Warp-Consolidation: A Novel Execution Model for GPUs."
Ang Li, Weifeng Liu, Linnan Wang, Kevin Barker, Shuaiwen Leon Song. In 32nd ACM International Conference on Supercomputing (ICS'18). (A new GPU programming model for synchronisation-critical applications).

[TACO]
"NUMA-Caffe: NUMA-Aware Deep Learning Neural Networks."
Probir Roy, Shuaiwen Leon Song, SRIRAM KRISHNAMOORTHY, Dipanjan Sengupta, Xu Liu. In ACM Transactions on Architecture and Code Optimization (TACO).
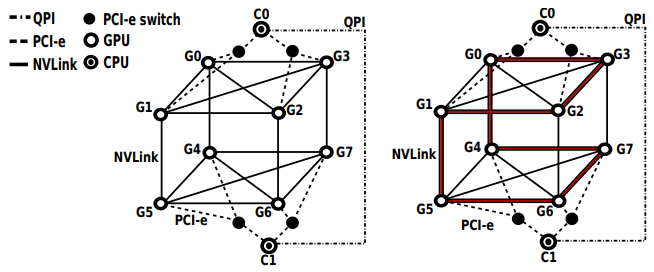
[TPDS]
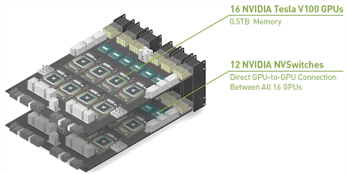
"Evaluating Modern GPU Interconnect: PCIe, NVLink, NV-SLI, NVSwitch and GPUDirect."
Ang Li, Shuaiwen Leon Song, Jieyang Chen, Jiajia Li, Xu Liu, Nathan R. Tallent, Kevin J. Barker. In IEEE Transactions on Parallel and Distributed Systems (TPDS).
[IISWC'18, Best Paper Finalist]
"Tartan: Evaluating Modern GPU Interconnect via a Multi-GPU Benchmark Suite."
Ang Li, Shuaiwen Leon Song, Jieyang Chen, Jiajia Li, Xu Liu, Nathan R. Tallent, Kevin J. Barker. In 2018 IEEE International Symposium on Workload Characterisation (IISWC).
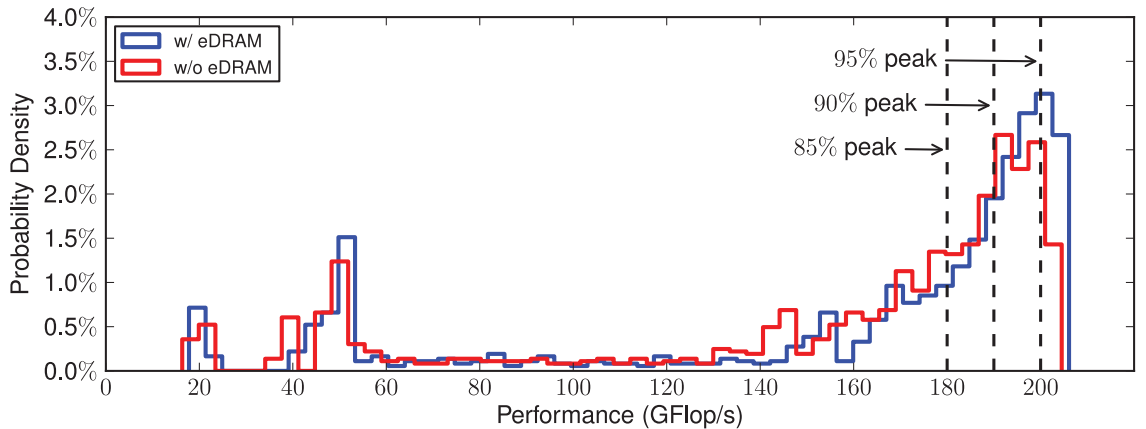
[SC'17, Best Paper Finalist, DoE Research Highlight article]
"Exploring and analysing the real impact of modern on-package memory on HPC scientific kernels."
Ang Li, Weifeng Liu, Mads Ruben Burgdorff Kristensen, Brian Vinter, Hao Wang, Kaixi Hou, Andres Marquez, Shuaiwen Leon Song. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC '17). (Acceptance rate: 61/327=18.6%; First research investigating performance impact of introducing on-package memory into memory hierarchy on a large spectrum of fundamental HPC scientific kernels and provide formalised modelling scheme for easy performance analysis at large scale. It receives SC'17 best paper finalist and DoE research highlight.)
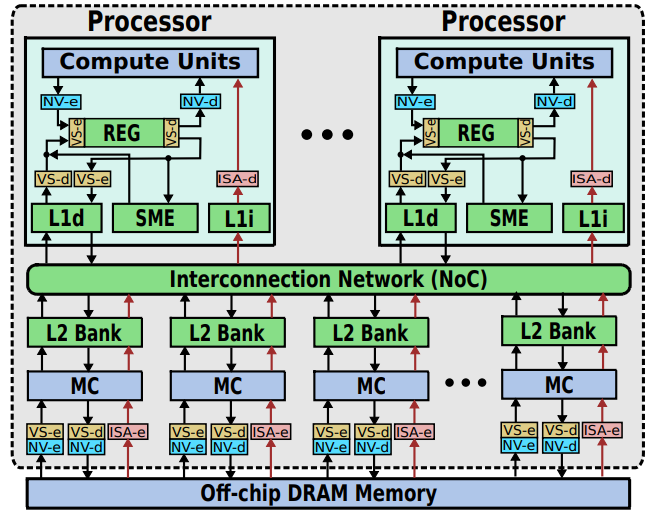
[MICRO-50]
"BVF: enabling significant on-chip power savings via bit-value-favour for throughput processors."
Ang Li, Wenfeng Zhao, Shuaiwen Leon Song. In Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO '17). (Acceptance rate:18.6%).

[ASPLOS-17, HiPEAC paper award]
"Locality-Aware CTA Clustering for Modern GPUs."
Ang Li, Shuaiwen Leon Song, Weifeng Liu, Xu Liu, Akash Kumar, Henk Corporaal. In Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS '17). (Acceptance rate:17.4%)
Video
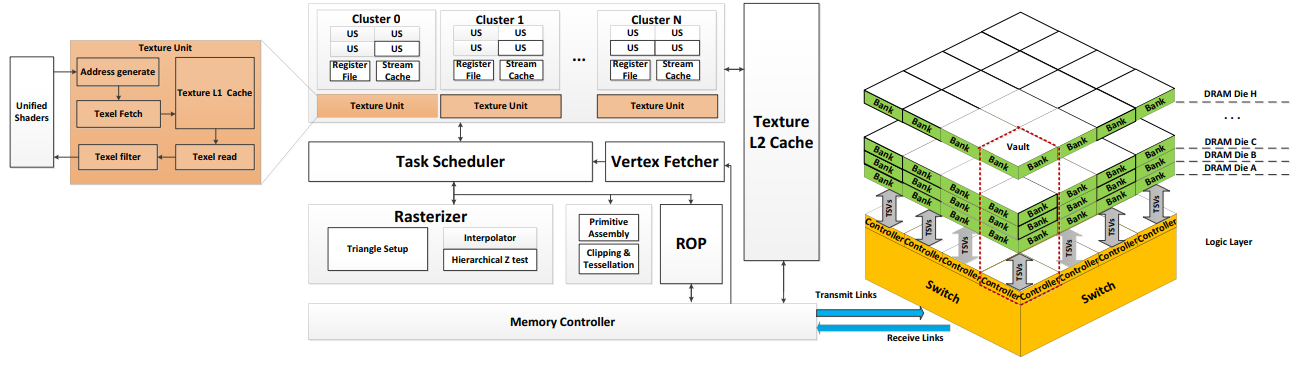
[HPCA'17]
"Processing-in-Memory Enabled Graphics Processors for 3D Rendering."
Chenhao Xie, Shuaiwen Leon Song, Xin Fu. In n 2017 IEEE International Symposium on High Performance Computer Architecture (HPCA). (Acceptance rate:21.6%; Using processing-in-memory technique along with graphics software pipeline re-design to accelerate modern rendering efficiency. )
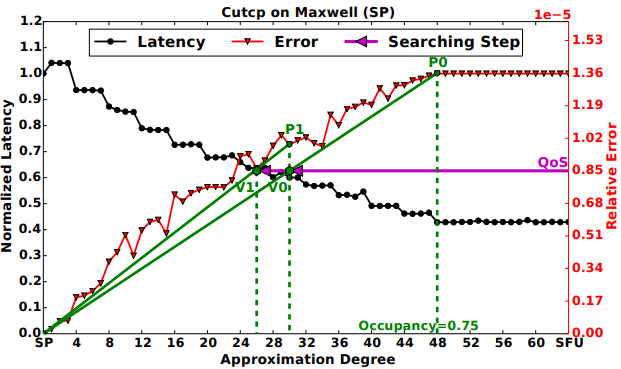
[ICS'16]
"SFU-Driven Transparent Approximation Acceleration on GPUs."
Ang Li, Shuaiwen Leon Song, Mark Wijtvliet, Akash Kumar, Henk Corporaal. In 30th ACM International Conference on Supercomputing (ICS). (Interesting concept about approximation units on modern many-core architectures and how they collaborate together in system to achieve dynamic performance-accuracy trade-offs.)
[HPDC'16]
"SMT-Aware Instantaneous Footprint Optimization."
Probir Roy, Xu Liu, Shuaiwen Leon Song. In 25th ACM international Symposium on High-Performance and Distributed Computing (HPDC). (Identifying, debugging and fixing false sharing on multicore processors.)
[ICS'15]
"Locality-Driven Dynamic GPU Cache Bypassing."
Chao Li, Shuaiwen Leon Song, Hongwen Dai, Albert Sidelnik, Siva Hari, Huiyang Zhou In 29th ACM International Conference on Supercomputing (ICS).
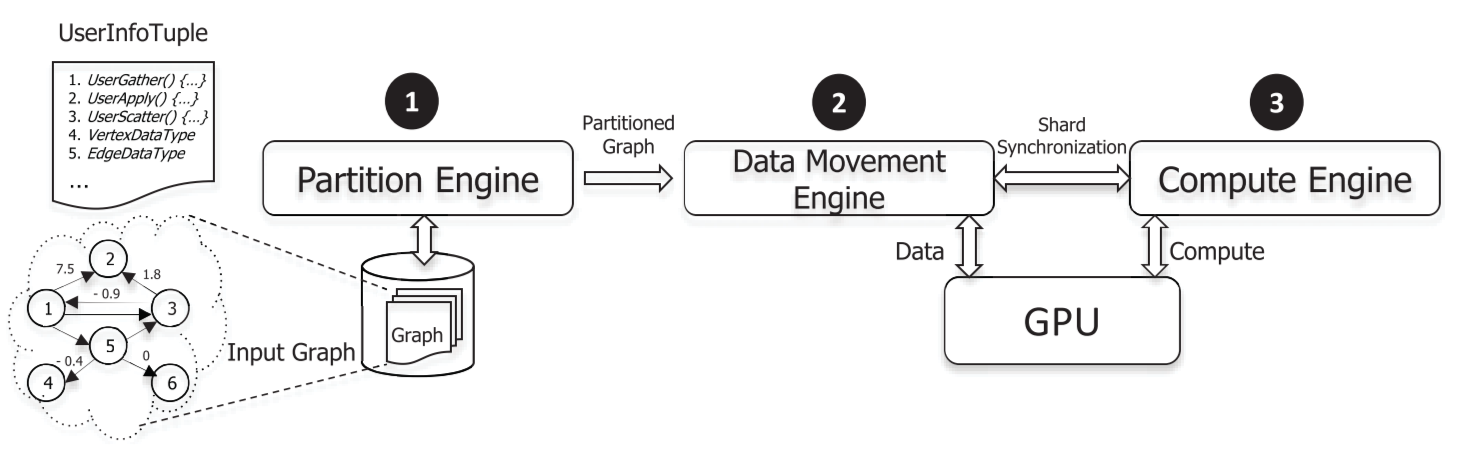
[SC'15, Best Paper Finalist]
"GraphReduce: processing large-scale graphs on accelerator-based systems."
Dipanjan Sengupta, Shuaiwen Leon Song, Kapil Agarwal, Karsten Schwan. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC '15). (Acceptance rate:18.5%)
